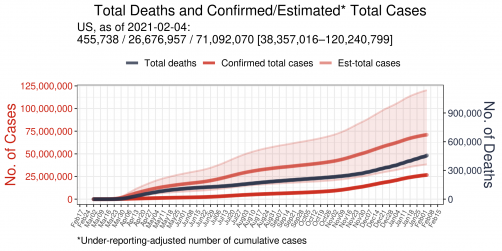
Estimate of actual number of cumulative cases after adjusting for underreporting versus the number of reported, or lab-confirmed, cases. (Shaded area represents possible range of cumulative cases given uncertainties surrounding COVID-19.) Courtesy of Jungsik Noh via GitHub
World health experts have long suspected that the incidence of COVID-19 has been higher than reported. Now, a machine-learning algorithm developed at UT Southwestern estimates that the number of COVID-19 cases in the U.S. since the pandemic began is nearly three times that of confirmed cases.
The algorithm, described in a study published today in PLOS ONE, provides daily updated estimates of total infections to date as well as how many people are currently infected across the U.S. and in 50 countries hardest hit by the pandemic.
As of Feb. 4, according to the model’s calculations, more than 71 million people in the U.S. – 21.5 percent of Americans – had contracted COVID-19. That compares with the substantially smaller 26.7 million publicly reported number of confirmed cases, says Jungsik Noh, PhD, a UT Southwestern assistant professor in the Lyda Hill Department of Bioinformatics and first author of the study.
Of those 71 million Americans estimated to have had COVID-19, 7 million (2.1 percent of the U.S. population) had current infections and were potentially contagious on Feb. 4, according to the algorithm.
Noh’s written study is based on calculations completed in September. At that time, it reports, the number of actual cumulative cases in 25 of the 50 hardest-hit countries was five to 20 times greater than the confirmed case numbers then suggested.
Looking at the current information available on the online algorithm, the estimates are now closer to the reported numbers – but still much higher. On Feb. 4, Brazil had more than 36 million cumulative cases as estimated by the algorithm, almost four times more than the 9.4 million confirmed cases reported. France had 14 million versus the 3.2 million reported. And the United Kingdom had almost 25 million instead of about 4 million – more than six times as many. Mexico, an outlier, had nearly 15 times its reported number of cases – 27.6 million rather than 1.9 million confirmed cases.
“The estimates of actual infections reveal for the first time the true severity of COVID-19 across the U.S. and in countries worldwide,” says Noh.
The algorithm uses the number of reported deaths – thought to be more accurate and complete than the number of lab-confirmed cases – as the basis for its calculations. It then assumes an infection fatality rate of 0.66 percent, based on an earlier study of the pandemic in China, and considers other factors such as the average number of days from the onset of symptoms to death or recovery. It also compares its estimate with the number of confirmed cases to calculate a ratio of confirmed-to-estimated infections.
Much is still uncertain about COVID-19 – particularly the death rate – and the estimates are therefore rough, Noh says. But he believes the model’s estimates are more accurate and leave out fewer cases than the confirmed ones currently used as guidance for public health policies. Having a more comprehensive estimate about the prevalence of the disease is important, Noh adds.
“These are critical statistics about the severity of COVID-19 in each region. Knowing the true severity in different regions will help us effectively fight against the virus spreading,” he explains. “The currently infected population is the cause of future infections and deaths. Its actual size in a region is a crucial variable required when determining the severity of COVID-19 and building strategies against regional outbreaks.”
In the U.S., infection rates vary widely by state. California has had almost 7 million infections since the pandemic’s start compared with New York’s 5.7 million, according to the algorithm’s projections for Feb. 4. Also, the model estimated California had 1.3 million active cases on that date, affecting 3.4 percent of the state’s population.
Other model estimates for Feb. 4: In Pennsylvania, 11.2 percent of the population had current infections – the highest rate of any state, compared with a low of 0.15 percent of those living in Minnesota; in New York, an early hot spot, 528,000 people had active infections, or about 2.7 percent of its population. Meanwhile, in Texas, 2.3 percent had current infections.
Noh says he developed the algorithm last summer while trying to decide whether to send his sixth-grade daughter back to school in person. There was nowhere to find the data he needed to gauge the safety of doing so, he says.
Once he built the machine algorithm, he discovered the area where he lived had about a 1 percent current infection rate. So his daughter went to school.
Noh checked his findings by comparing his results with existing prevalence rates found in several studies that used blood tests to check for antibodies to the SARS-CoV-2 virus, which causes COVID-19. For most of the areas tested, his algorithm’s estimates of infections closely corresponded to the percentage of people who had tested positive for the antibodies, according to the PLOS ONE study.
The online model uses COVID-19 death data from Johns Hopkins University and The COVID Tracking Project, a volunteer organization founded to help track COVID-19, to run its daily updates. However, the estimates published in the PLOS ONE study date from Sept. 3. At that time, about 10 percent of the U.S. population had been infected with COVID-19, based on Noh’s algorithm.
Gaudenz Danuser, PhD, chair of the Lyda Hill Department of Bioinformatics and professor of cell biology, was senior author of the study. He also holds the Patrick E. Haggerty Distinguished Chair in Basic Biomedical Science.
Funding came from Lyda Hill Philanthropies.
Source: UT Southwestern Medical Center
Be the first to comment on "COVID-19 Infections in the U.S. Nearly Three Times Greater Than Reported, Model Estimates"